Promotion motivation and prevention motivation are two distinct motivational orientations, rooted in the promotion and prevention motivation systems, that influence whether one focuses on approaching gains and avoiding non-gains as well as approaching non-losses and avoiding losses, respectively. Individuals with a chronic preference for promotion focus are more likely to select promotion goals (that produce gains) and eager strategies; whereas people with a dominant prevention focus are more likely to select prevention goals (that produce non-losses) and vigilant strategies. More than two decades of reseach on regulatory focus theory shows motivational orientation influences health behavior, work behavior, and prosocial behavior (Scholer et al., 2019). However, promotion/prevention motivation has not been integrated with prosocial motivation to explain the goal pursuit strategy for prosocial behavior that benefits the health, safety, and wellbeing of others. In this pilot study, we examine the seven mindset types of prosocial regulatory focus: promote care, prevent harm, fail to care, fail to harm, maintain care, respond to harm, and flipping from harm to care.
Rows: 121 Columns: 67
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (10): test, demo1, demo2, demo3, demo4, demo5, demo6, demo7, trainingda...
dbl (56): participantID, consent, PROMOTECARE, PREVENTHARM, FAILCARE, FAILH...
time (1): time
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
Show the code
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Show the code
library(tidyr)library(ggrain)
Registered S3 methods overwritten by 'ggpp':
method from
heightDetails.titleGrob ggplot2
widthDetails.titleGrob ggplot2
1 Descriptives
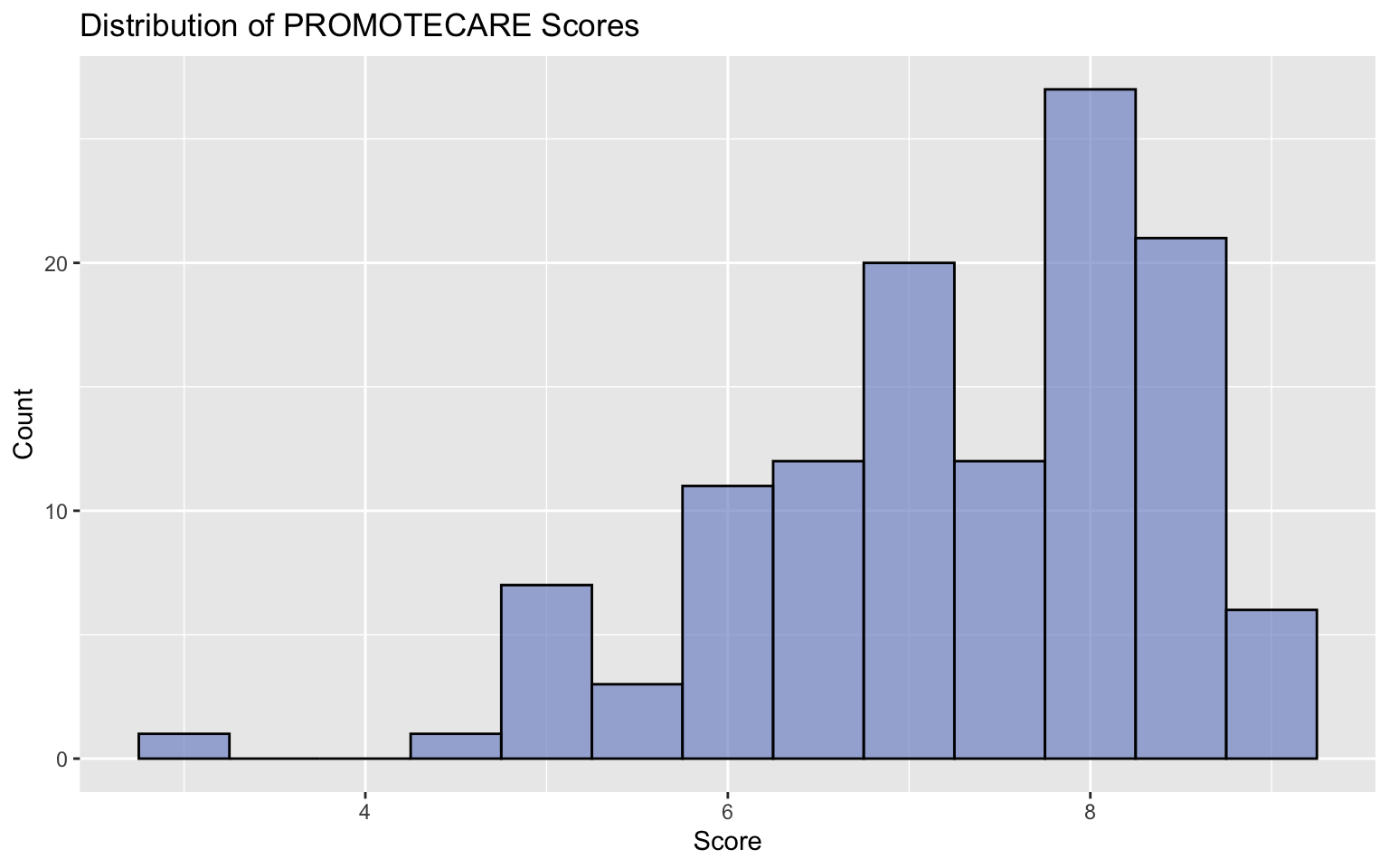
1.1 Distribution of Promoting Care Mindset
Show the code
## Distribution of PROMOTECAREdistri_of_procare <-ggplot(df, aes(x=PROMOTECARE)) +geom_histogram(binwidth=0.5, fill="#8297ce", color ="black", alpha=0.7) +labs(title="Distribution of PROMOTECARE Scores", x="Score", y="Count")distri_of_procare
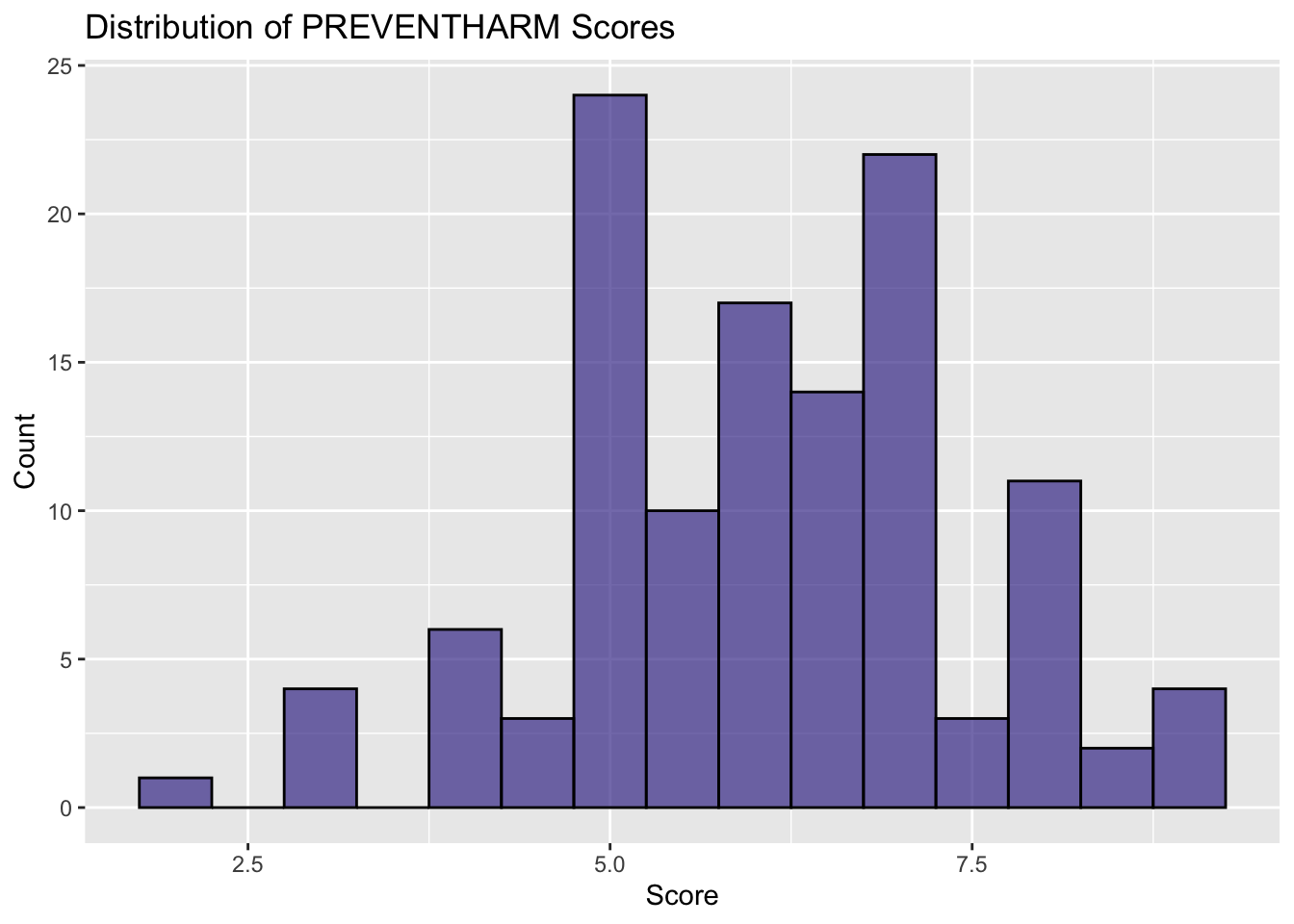
1.2 Distribution of Preventing Harm Mindset
Show the code
distri_of_preharm <-ggplot(df, aes(x=PREVENTHARM)) +geom_histogram(binwidth=0.5, fill="#453a98", color ="black", alpha=0.7) +labs(title="Distribution of PREVENTHARM Scores", x="Score", y="Count")distri_of_preharm
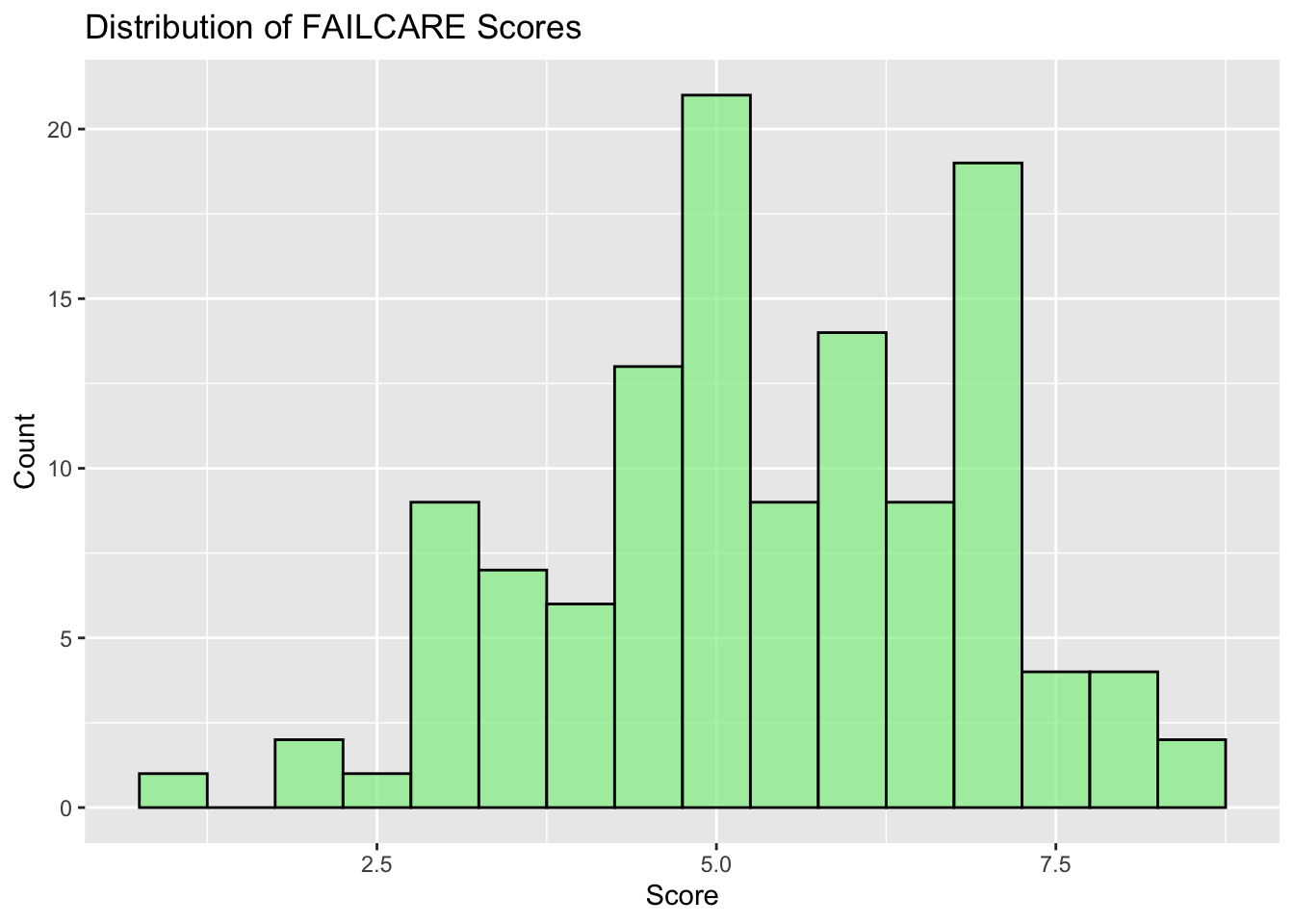
1.3 Distribution of Failing to Care Mindset
Show the code
## Distribution of FAILCARE#| echo: truedistri_of_failcare <-ggplot(df, aes(x=FAILCARE)) +geom_histogram(binwidth=0.5, fill="#90EE90", color ="black", alpha=0.7) +labs(title="Distribution of FAILCARE Scores", x="Score", y="Count")distri_of_failcare
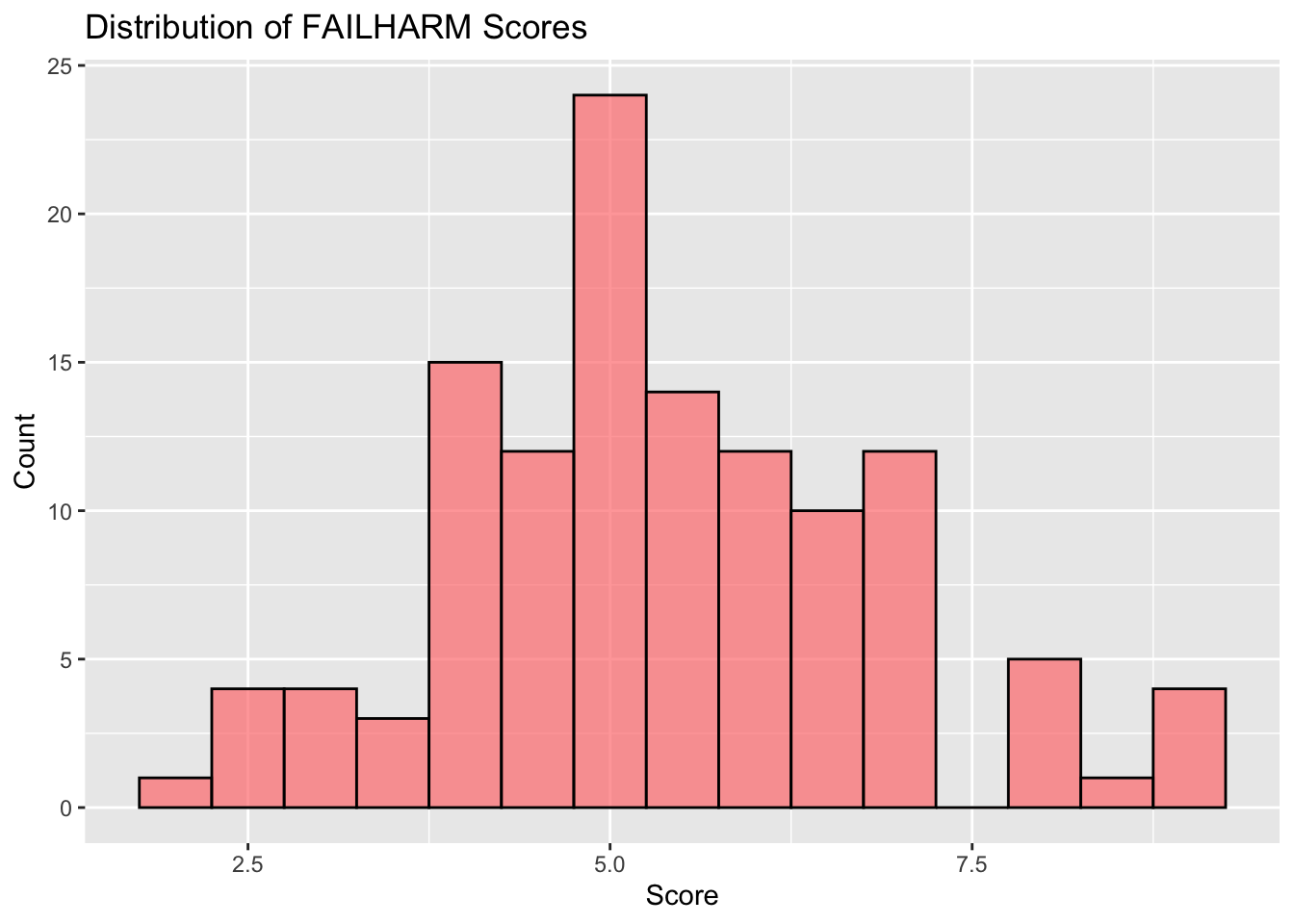
1.4 Distribution of Failing to Prevent Harm Mindset
Show the code
## Distribution of FAILHARMdistri_of_failharm <-ggplot(df, aes(x=FAILHARM)) +geom_histogram(binwidth=0.5, fill="#FF7F7F", color ="black", alpha=0.7) +labs(title="Distribution of FAILHARM Scores", x="Score", y="Count")distri_of_failharm
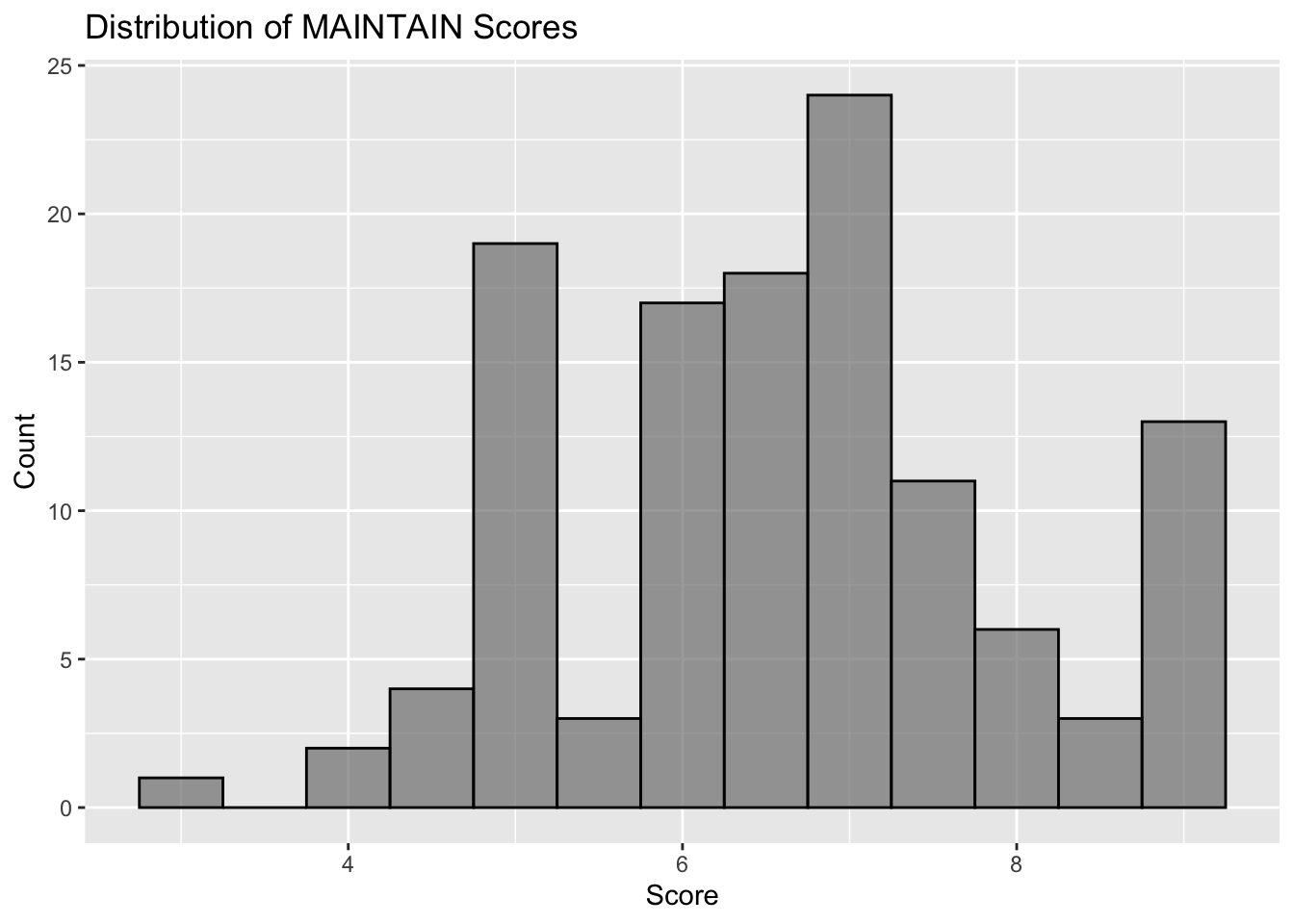
1.5 Distribution of Maintaining Care Mindset
Show the code
## Distribution of MAINTAINdistri_of_maintain <-ggplot(df, aes(x=MAINTAIN)) +geom_histogram(binwidth=0.5, fill="#808080", color ="black", alpha=0.7) +labs(title="Distribution of MAINTAIN Scores", x="Score", y="Count")distri_of_maintain
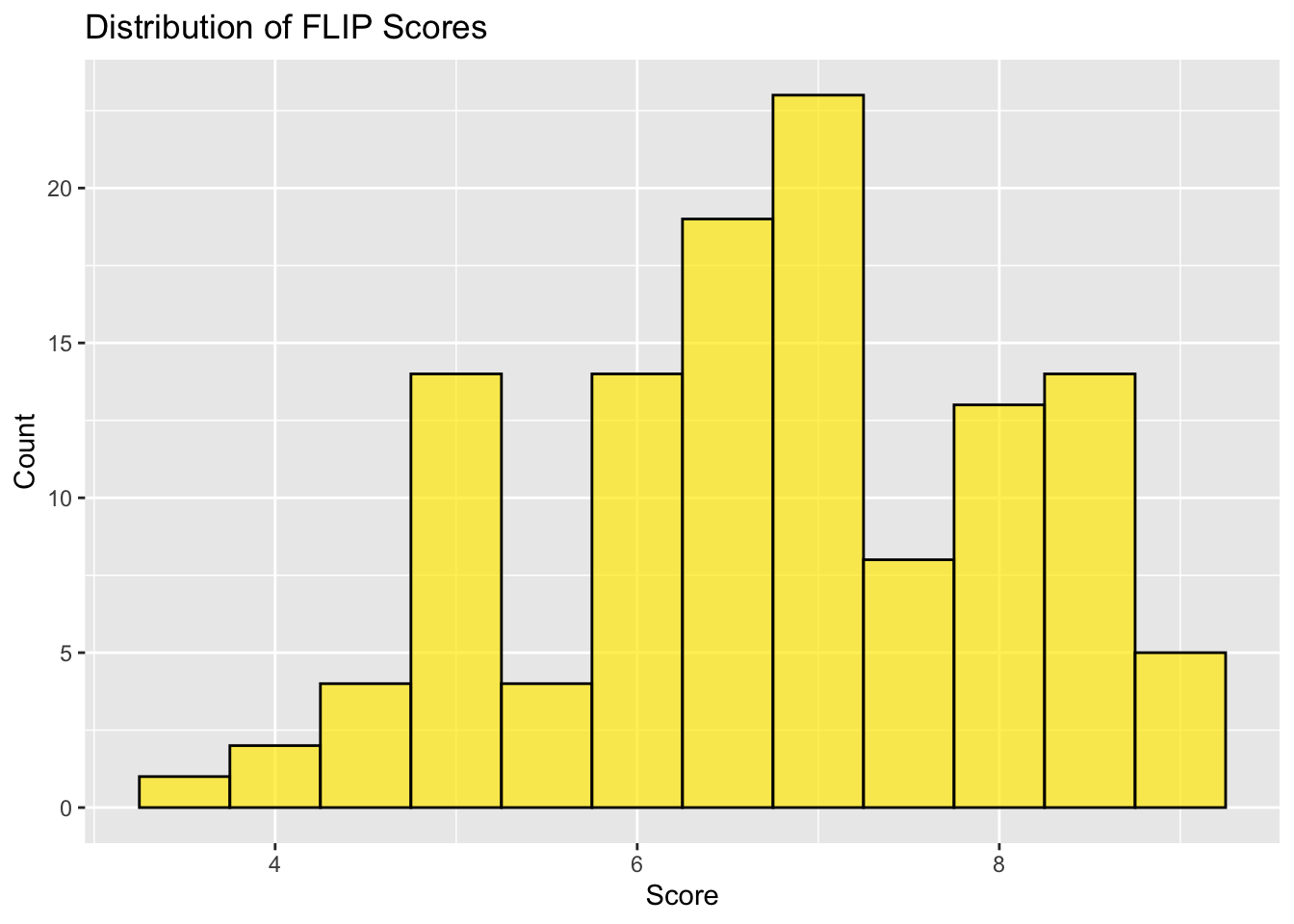
1.6 Distribution of Flipping from Harm to Care Mindset
Show the code
## Distribution of FLIPdistri_of_flip <-ggplot(df, aes(x=FLIP)) +geom_histogram(binwidth=0.5, fill="#FFEA00", color ="black", alpha=0.7) +labs(title="Distribution of FLIP Scores", x="Score", y="Count")distri_of_flip
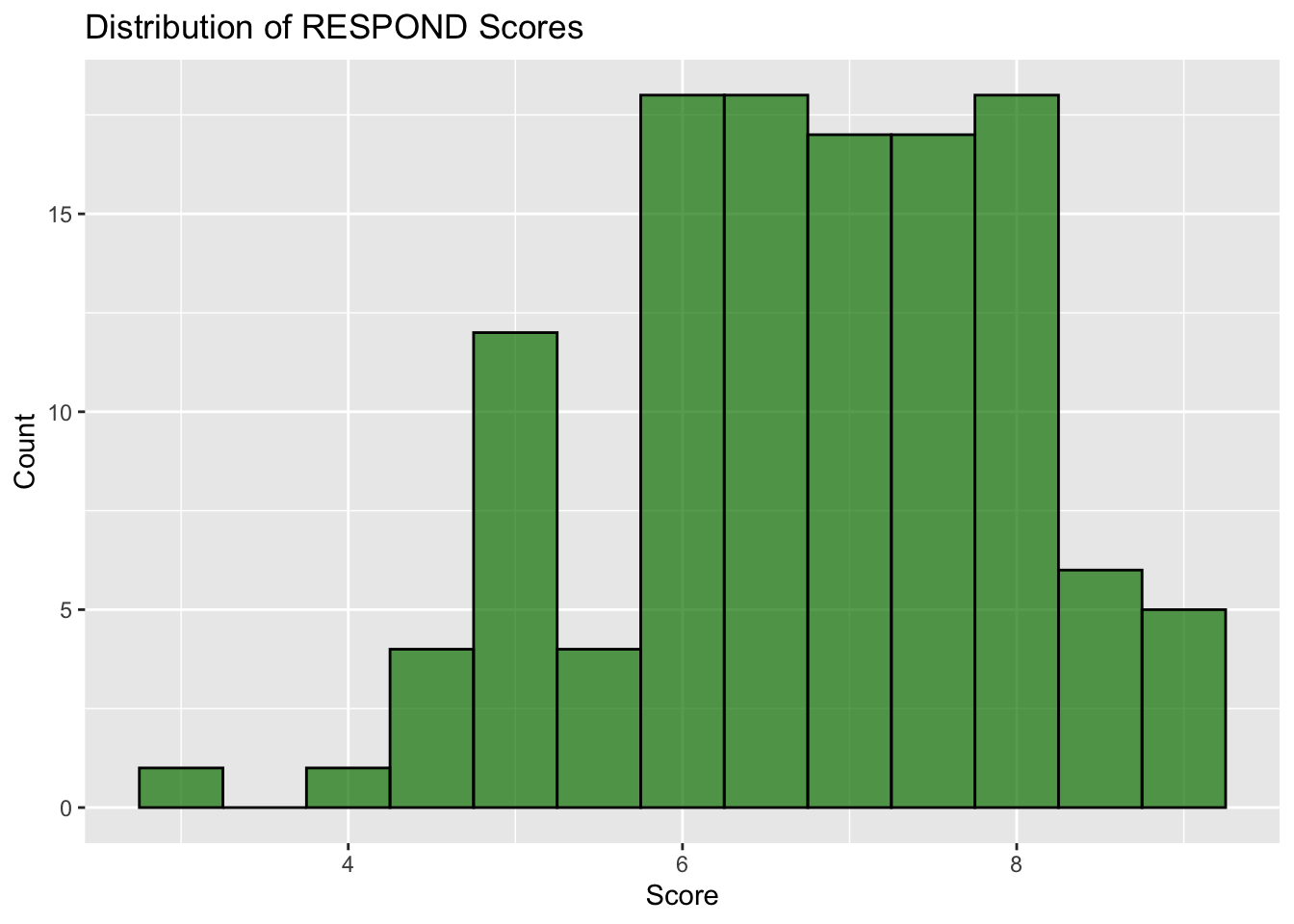
1.7 Distribution of Responding to Harm
Show the code
## Distribution of RESPONDdistri_of_respond <-ggplot(df, aes(x=RESPOND)) +geom_histogram(binwidth=0.5, fill="#008000", color ="black", alpha=0.7) +labs(title="Distribution of RESPOND Scores", x="Score", y="Count")distri_of_respond
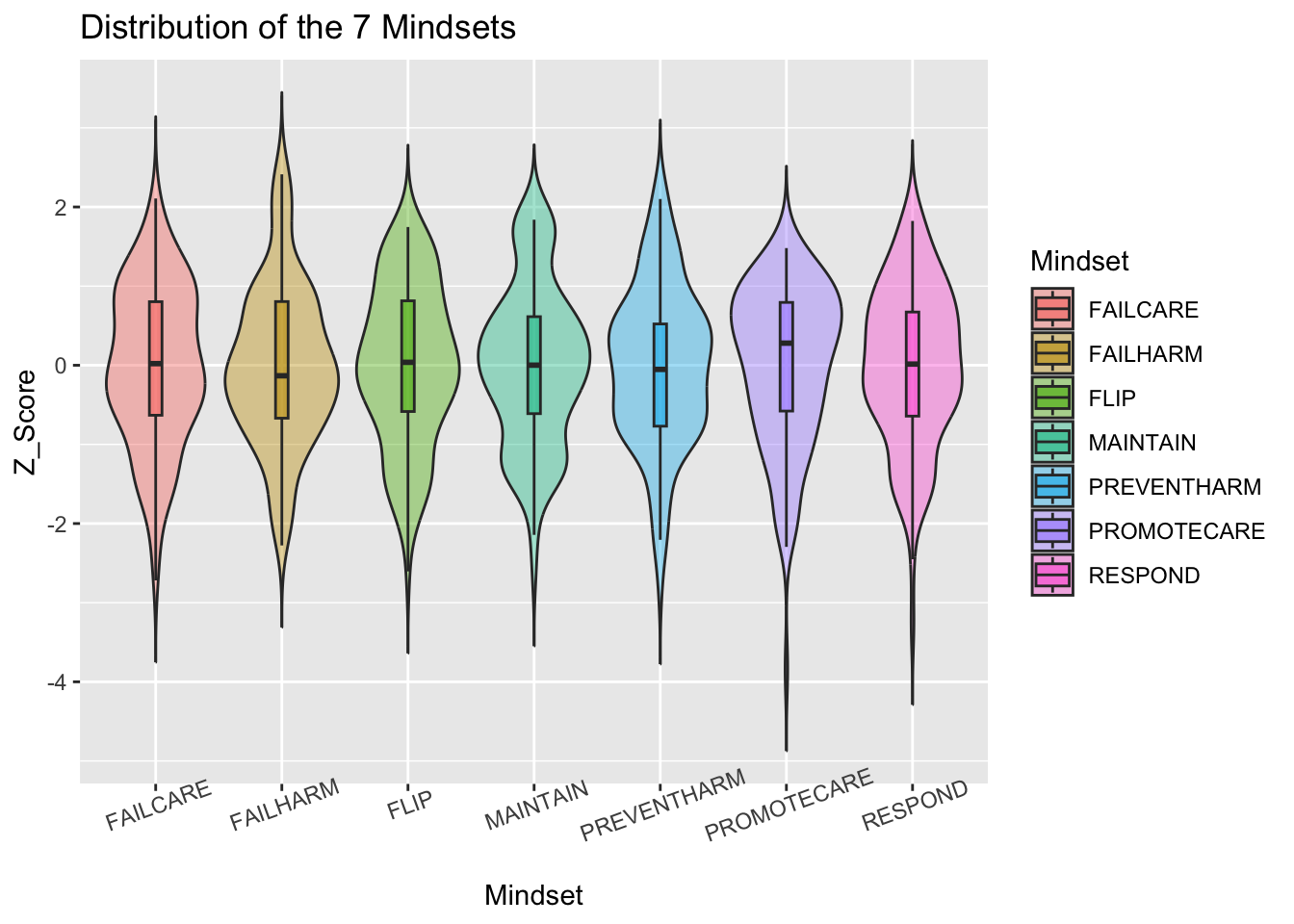
1.8 Distribution of Seven Mindsets
Show the code
mindsets <-c("PROMOTECARE", "PREVENTHARM", "FAILCARE", "FAILHARM", "MAINTAIN", "FLIP", "RESPOND")## standardize all mindset variables to z-scoresdf_z <- df %>%mutate(across(all_of(mindsets), ~as.numeric(scale(.x))))## reshape to long formatdf_long <- df_z %>%select(all_of(mindsets)) %>%pivot_longer(cols =everything(), names_to ="Mindset", values_to ="Z_Score")df_long
## Distribution of the 7 mindsetsdistr_allmindset <-ggplot(df_long, aes(x = Mindset, y = Z_Score, fill = Mindset)) +geom_violin(trim =FALSE, alpha =0.4) +geom_boxplot(width =0.1, outlier.shape =NA, alpha =0.6) +labs(title ="Distribution of the 7 Mindsets",y ="Z_Score", x ="Mindset") +theme(axis.text.x =element_text(angle =20))distr_allmindset
2 Mindset Associations
The correlation heatmap shows the correlations among the seven mindsets with green-yellow indicating the strongest, positive correlations.
FAILHARM & FAILCARE: Since both mindsets represent anxiety about not meeting one’s caregiving goals, it makes sense that they are positively correlated (r = 0.66).
PROMOTECARE & MAINTAIN: A strong correlation (r = 0.67) suggests that individuals who emphasize promote care also tend to maintain it.This makes sense because those who focus on creating positive outcomes (PROMOTECARE) are also likely to be committed to sustaining those outcomes (MAINTAIN).
(expand.grid(): creates all combinations of the column names (X) and row names (Y) of the matrix. https://www.statology.org/expand-grid-r/)
Show the code
## Heatmap of all mindsets relationships## filter out all the mindsetsallmindsets <- df %>%select(PROMOTECARE, PREVENTHARM, FAILCARE, FAILHARM, MAINTAIN, FLIP, RESPOND)## computes the correlation matrix between all selected variables ("complete.obs" make sure we only use non-missing data)corr_matrix <-cor(allmindsets, use="complete.obs")corr_matrix
## creates all combinations of the column names (X) and row names (Y) of the matrixheatmap_data <-expand.grid(X =colnames(corr_matrix), Y =rownames(corr_matrix))## convert correlation matrix into long vector, add a new column z contain the corr_matrix for each (x, y) pairheatmap_data$Z <-as.vector(corr_matrix)heatmap_data
## convert X and Y to factors with desired orderdesired_order <-c("PROMOTECARE", "PREVENTHARM", "MAINTAIN", "RESPOND", "FLIP", "FAILCARE", "FAILHARM")heatmap_data$X <-factor(heatmap_data$X, levels = desired_order)heatmap_data$Y <-factor(heatmap_data$Y, levels = desired_order)
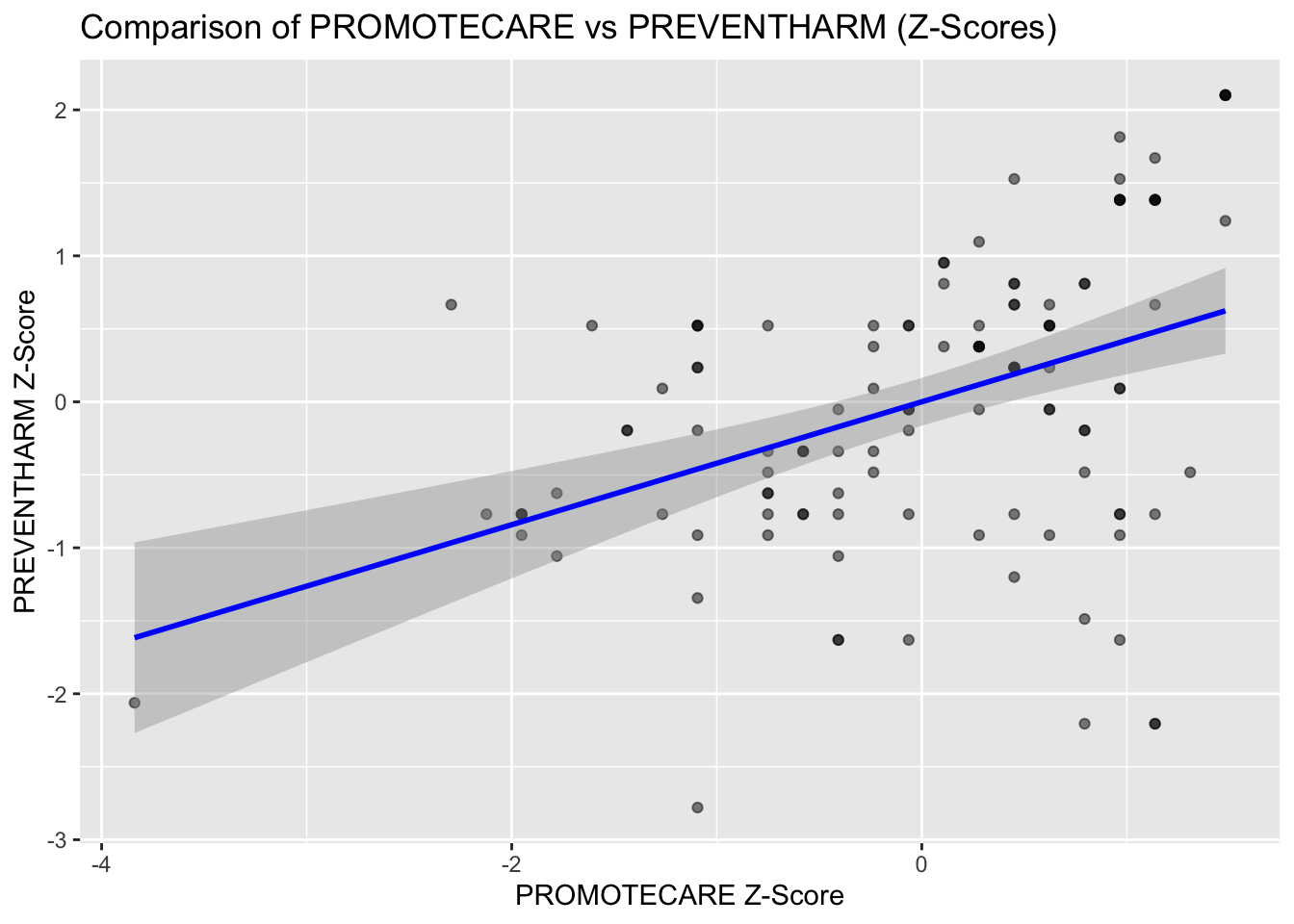
## Standardize variables to z-scoresdf$PROMOTECARE_zscore <-as.numeric(scale(df$PROMOTECARE))df$PREVENTHARM_zscore <-as.numeric(scale(df$PREVENTHARM))## compare promotecare & preventharm by scatter plotggplot(df, aes(x = PROMOTECARE_zscore, y = PREVENTHARM_zscore)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", color ="blue") +labs(title ="Comparison of PROMOTECARE vs PREVENTHARM (Z-Scores)",x ="PROMOTECARE Z-Score", y ="PREVENTHARM Z-Score")
`geom_smooth()` using formula = 'y ~ x'
3 Differences by Sociodemographics
3.1 Promoting Care Mindset by Gender Identity
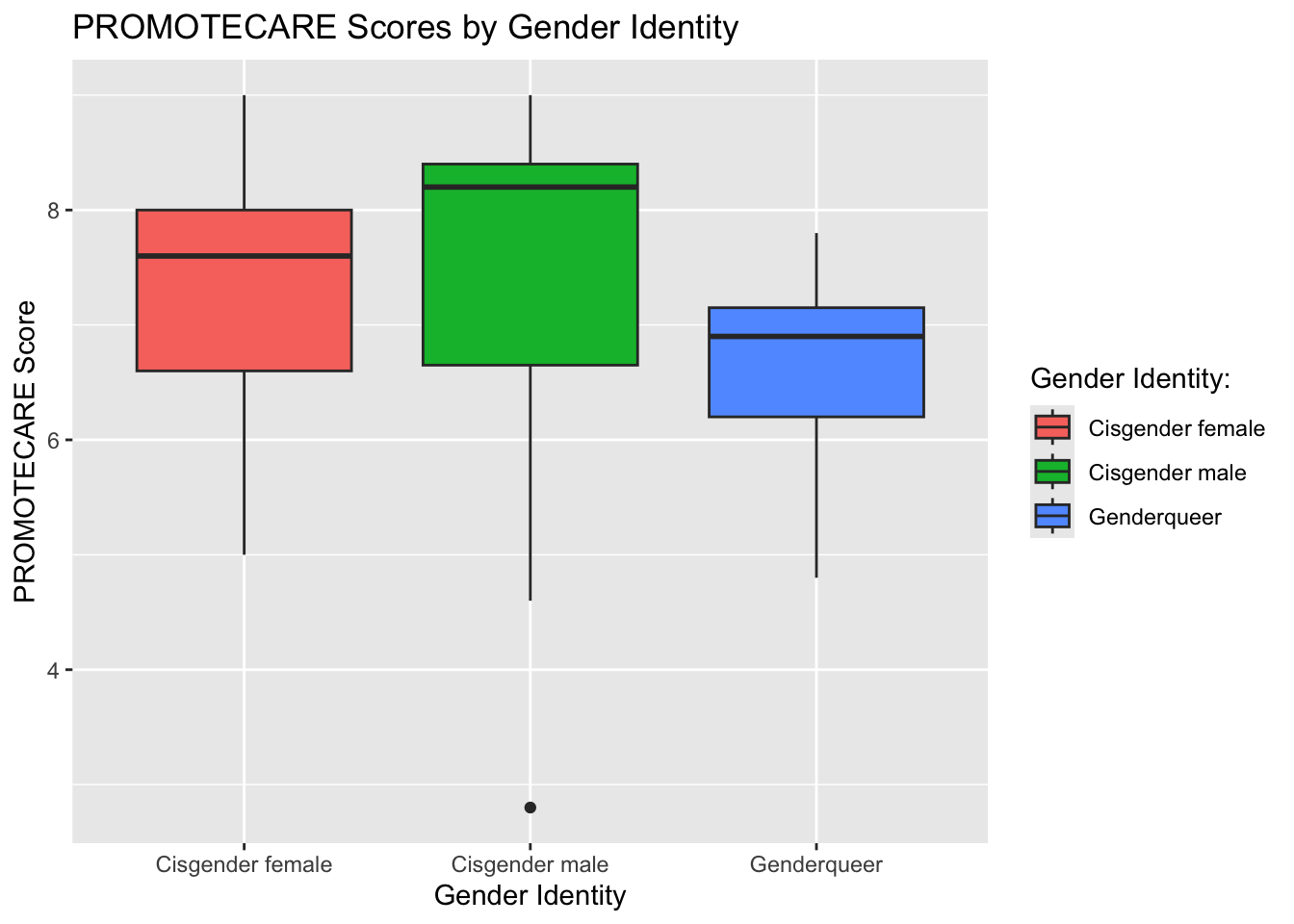
According to the data, individuals who identify as cismen tend to score higher on the PROMOTECARE measure compared to other gender identities in the sample.
Show the code
## PROMOTECARE score distributions across gender identitygender_procare <-ggplot(df, aes(x = demo1, y = PROMOTECARE, fill = demo1)) +geom_boxplot() +labs(title ="PROMOTECARE Scores by Gender Identity", x ="Gender Identity", y ="PROMOTECARE Score")+guides(fill =guide_legend(title ="Gender Identity:"))gender_procare
3.2 Promoting Care Mindset by Age
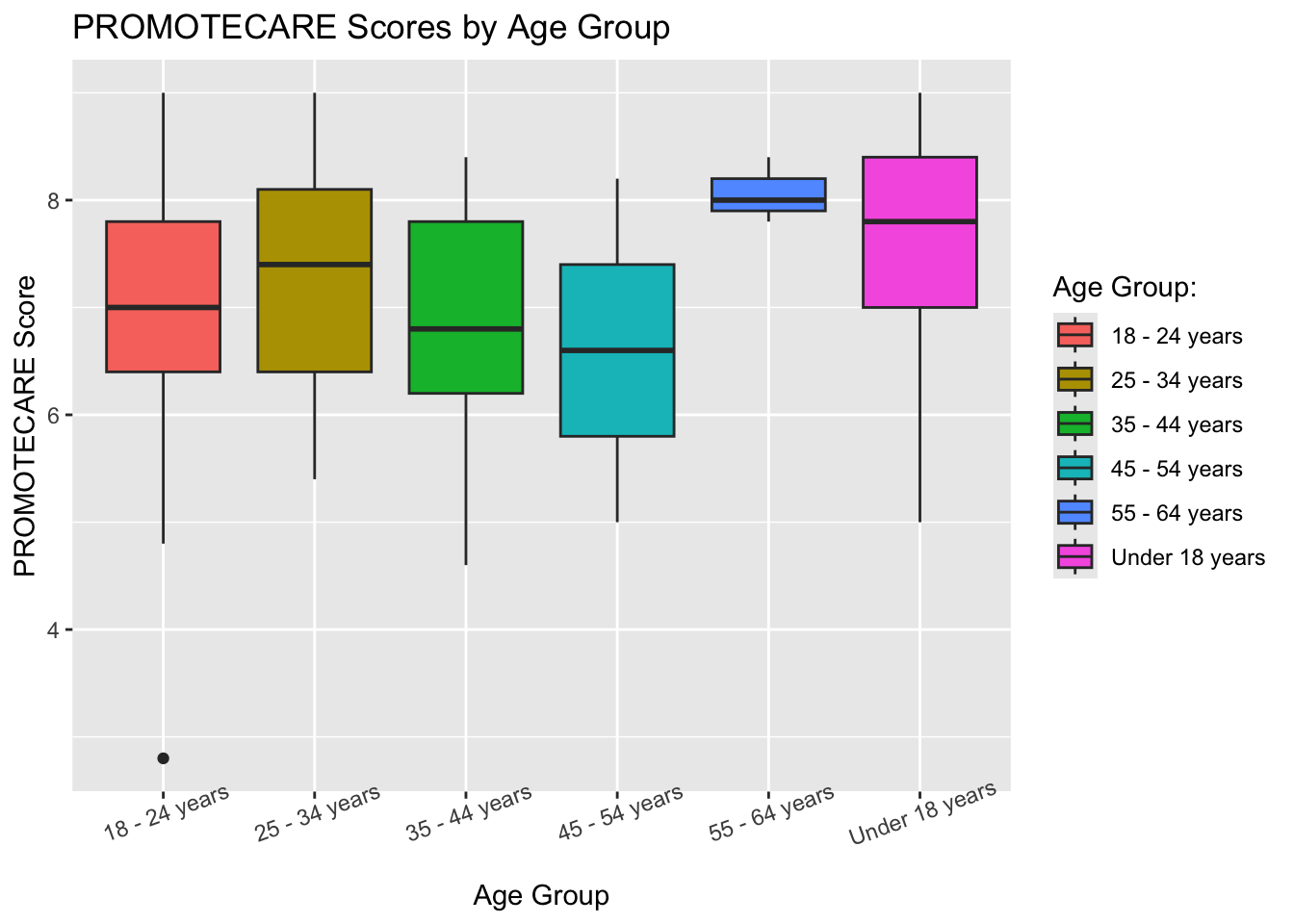
Age group does not appear to have a strong correlation with the PROMOTECARE score, although individuals in the 55-64 age group tend to have higher PROMOTECARE scores, which means they may have a stronger focus on creating positive outcomes for others.
Show the code
## PROMOTECARE score distributions across age groupage_procare <-ggplot(df, aes(x = demo6, y = PROMOTECARE, fill = demo6)) +geom_boxplot() +labs(title ="PROMOTECARE Scores by Age Group", x ="Age Group", y ="PROMOTECARE Score")+guides(fill =guide_legend(title ="Age Group:"))+theme(axis.text.x =element_text(angle =20)) age_procare
3.3 Failing to Care Mindset by Racialized Identity
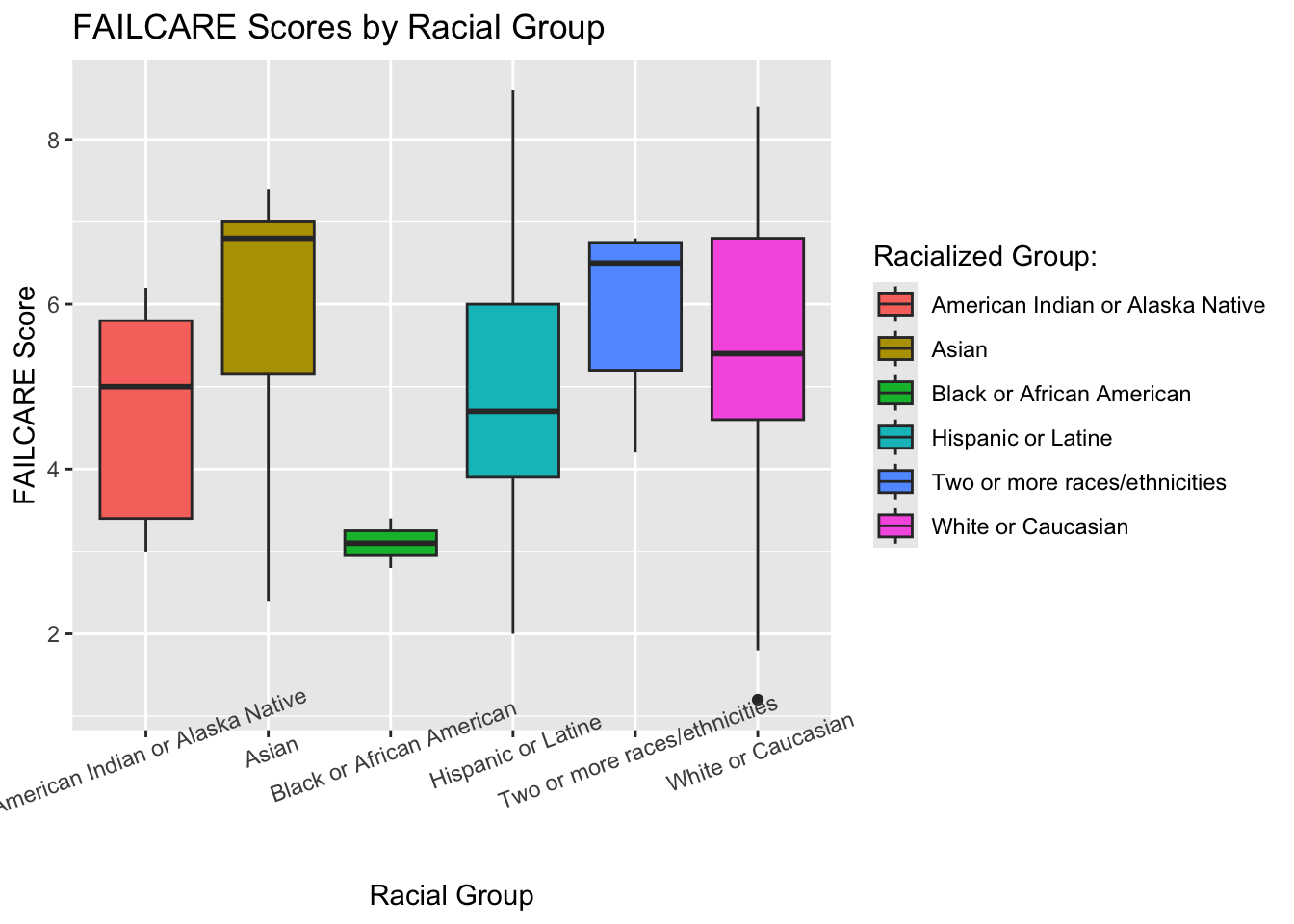
Racial group does not appear to have a strong correlation with the FAILCARE score, although people who identify as Asian tend to have higher FAILCARE scores, which means they have a greater worries about failing to create positive outcomes for others.
Show the code
## FAILCARE score distributions across racial groupracial_failcare <-ggplot(df, aes(x = demo2, y = FAILCARE, fill = demo2)) +geom_boxplot() +labs(title ="FAILCARE Scores by Racial Group", x ="Racial Group", y ="FAILCARE Score")+guides(fill =guide_legend(title="Racialized Group:"))+theme(axis.text.x =element_text(angle =20)) racial_failcare
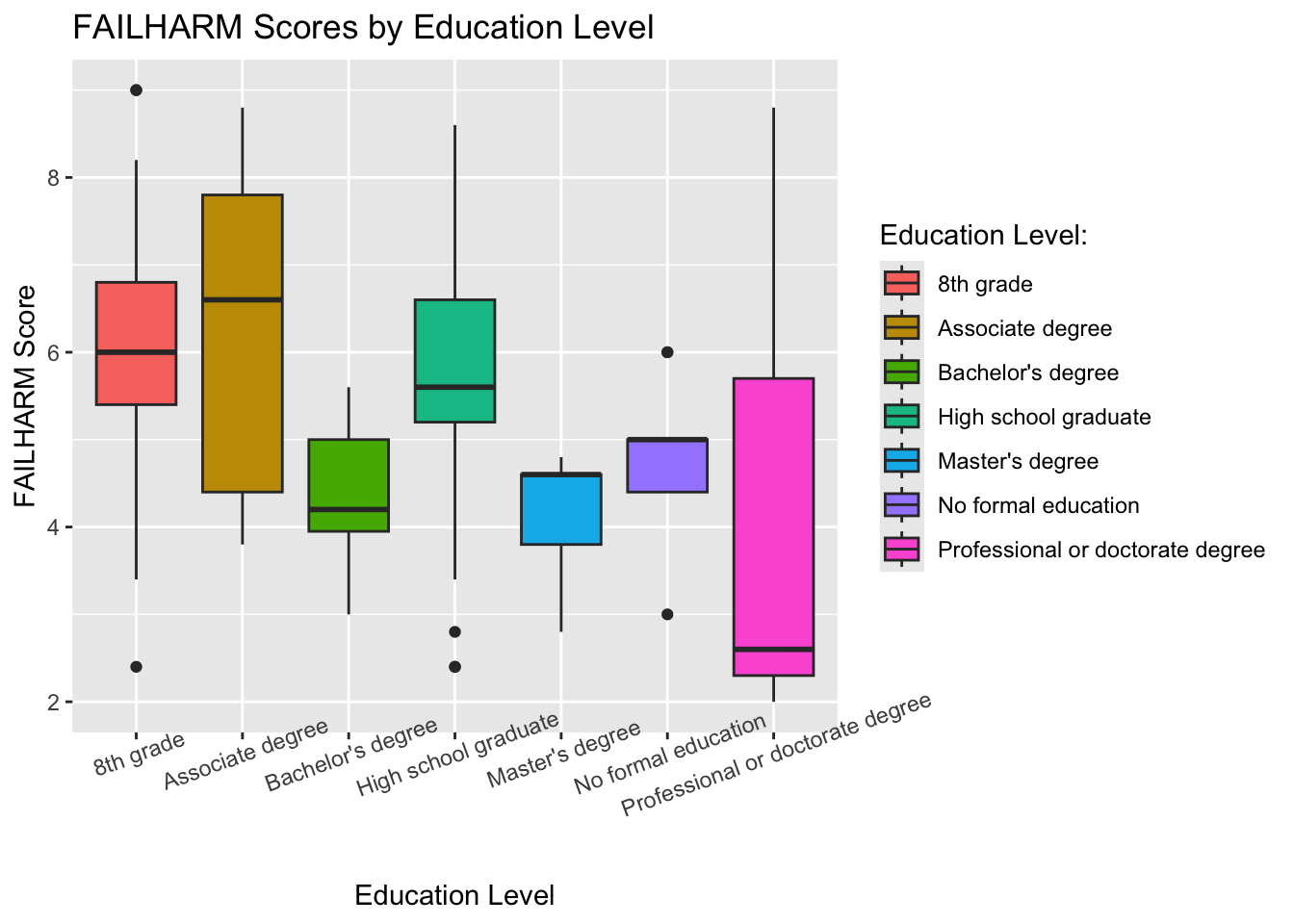
3.4 Failing to Prevent Harm Mindset by Educational Level
As education level increases, individuals endorse lower scores on failing to prevent harm mindset. Simply, this means more educated people have a less anxiety about failing to prevent negative outcomes.
Show the code
## FAILHARM score distributions across education leveleducation_preharm <-ggplot(df, aes(x = demo3, y = FAILHARM, fill = demo3)) +geom_boxplot() +labs(title ="FAILHARM Scores by Education Level", x ="Education Level", y ="FAILHARM Score")+guides(fill =guide_legend(title ="Education Level:"))+theme(axis.text.x =element_text(angle =20))education_preharm
3.5 Paired Comparisons of PROMOTECARE vs. PREVENTHARM